
Following the development in Peers et. al.’s Compressive Light Transport Sensing (download), the light transport problem can be described by the following matrix equation:

where
is a
-dimensional vector, where
is an
-dimensional vector, where
is a transfer matrix of size
.
The 


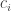

Each 

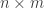


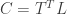
or, if you prefer to write the signal we want to reconstruct at the end,

Notice that the above equation gives rise to 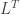
Suppose that each 


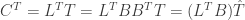
where 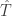
The theory of compressive sensing states that, if 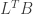
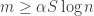
some constant 
Application to Precomputed Radiance Transfer?
Can we apply the above compressive sensing framework to PRT? After all, the core tasks of image relighting and PRT are the same: learning the transfer function of each pixel. The difference is that measurements in PRT are done in computer by tracing rays.
It’s possible. In the scenario that you would like to relight a scene by a high resolution environmental map, say 
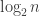
However, all of the above is not so impressive. First, it might take a very long time to render that 4000 images accurately. Second, we only assume that each pixel has one color, which either mean that the view is fixed or all the material is diffuse. Again, I don’t know how to handle variable views yet, but surveying more literature might help.
